

from:https://javaai.pig4cloud.com/introduction
课程介绍
本课程的主要目标是让Java开发者零基础入门AI,通过学习如何使用Java相关的AI框架,将大型语言模型和AI代理集成到现有系统中。我们将重点介绍如何使用LangChain4J等工具,在Java环境中构建高度定制化的AI应用程序。
零基础入门Java AI:探索大模型世界
随着人工智能(AI)技术的迅猛发展,越来越多的开发者开始将目光投向AI应用的开发。然而,目前市场上大多数AI框架和工具如LangChain、PyTorch等主要支持Python,而Java开发者常常面临工具缺乏和学习门槛较高的问题。
为了解决这一痛点,我们特别推出了《零基础入门Java AI》课程,旨在帮助Java开发者快速入门AI技术,探索如何将大模型(LLM)与业务系统无缝结合,实现智能化的业务流转。
课程目标
本课程的主要目标是让Java开发者零基础入门AI,通过学习如何使用Java相关的AI框架,将大型语言模型和AI代理集成到现有系统中。我们将重点介绍如何使用LangChain4J等工具,在Java环境中构建高度定制化的AI应用程序。
无代码大模型开发平台:局限与机遇
市场上已经出现了许多无代码的AI开发平台,如Dify和Coze,这些平台通过可视化界面和简单的配置实现AI功能,降低了开发门槛。然而,无代码平台的局限性也十分明显,尤其是在复杂业务场景中,无法灵活打通系统的各个环节,实现业务的流转和自动化。因此,深入学习编码开发平台依然是AI应用开发的核心路径。
Java AI 开发工具:LangChain4J与Spring AI
为了弥补Java开发者在AI领域的工具短板,市面上已经出现了几款针对Java的AI开发工具。其中,LangChain4J 和 Spring AI 是两款备受关注的解决方案。
提供标准化API,支持超过15个主流大模型提供商和嵌入存储。
提供工具箱,从低级提示词模板到高级AI服务,适合构建聊天机器人和检索增强生成(RAG)管道。
社区支持活跃,能够快速整合最新的AI技术,便于Java开发者将AI功能集成到现有项目中。
深度集成到Spring框架中,Java开发者可以轻松将AI功能嵌入到现有Spring项目中。
尽管Spring AI仍处于发展阶段,尚未发布正式版本,但其凭借Spring生态系统,具备了极强的扩展性和集成能力。
对比
Cursor: 革新性的AI代码编辑器
Cursor是一款真正意义上的AI编辑器,旨在提升编程效率。正如其官网所述:
“The AI Code Editor Built to make you extraordinarily productive, Cursor is the best way to code with AI.”
基于VSCode开发的Cursor,不同于大多数仅作为VSCode插件的AI编程工具,创造性地构建了一个高效的人机协作编程环境。
总结
《零基础入门Java AI》课程将带领大家深入理解大模型、AI代理及其在Java环境中的应用。通过学习LangChain4J和Spring AI等工具,将掌握如何在现有业务系统中集成AI,构建高效、智能的应用程序。无论是初学者还是经验丰富的Java开发者,都能从这门课程中获得实用的技能,为未来的AI开发打下坚实的基础。这个课程不仅能帮助你掌握AI的基础知识,更能让你在日益竞争的AI领域脱颖而出,成为业务智能化转型的核心推动者。
模型选择
本系列课程以 阿里百炼平台为主,辅以Ollama本地模型,同时也适用于其他模型,提供更广泛的适用性和灵活性。
所有调用均基于 OpenAI 协议标准,实现一致的接口设计与规范,确保多模型切换的便利性,提供高度可扩展的开发支持
Ollama 上手
安装Ollama
下载Ollama
访问Ollama官网(https://ollama.com),选择适合您操作系统的版本进行下载。
安装Ollama
双击下载的安装包,按照提示完成安装过程。
下载和运行模型
查看可用模型, 使用以下命令列出所有可用的模型:
ollama list
下载并运行模型
例如,要运行名为
qwen2.5的模型,可以输入:
ollama run qwen2.5:14b
与模型交互
模型运行后,您可以在终端中输入问题或指令,与模型进行交互,例如输入”北京美食推荐”。
lengleng@huawei ~ ollama run qwen2.5:14b
>>> Send a message (/? for help)
总结
国内大模型市场中,阿里通义系列无疑是首选,属于第一梯队。
尽管DeepSeek系列在价格和推理效率方面具备较高性价比,但其模型的全面性不及阿里云提供的服务。
阿里通义不仅覆盖了文本生成,还在向量、图形、视觉、声音等多模态领域表现出色,提供了更广泛的应用支持
LangChain4j 介绍
LangChain4j 是一个专为Java开发者设计的开源库,旨在简化将大型语言模型(LLM)集成到Java应用程序中的过程。它于2023年初开发,灵感来源于Python和JavaScript的LLM库,特别是为了填补Java领域在这一方面的空白。
LangChain4j 的核心功能
统一API:LangChain4j提供了一个标准化的API,使得开发者可以方便地接入15+个主流的LLM提供商(如OpenAI、Google 、阿里、 智谱)和15+个向量嵌入存储(Qdrant、Pinecone、Milvus)。这意味着开发者无需学习每个API的细节,可以轻松切换不同的模型和存储,而无需重写代码。
综合工具箱:该框架包含多种工具,从低级的提示模板、聊天记忆管理到高级模式(如AI服务和RAG)。这些工具帮助开发者构建从聊天机器人到完整的数据检索管道等多种应用。
多模态支持:LangChain4j支持文本和图像作为输入,能够处理更复杂的应用场景。
优势
模块化设计:LangChain4j采用模块化结构,使得不同功能可以独立使用,便于扩展和维护。
高层次抽象:框架在两个抽象层次上运行,允许开发者根据需要选择低级或高级API进行开发,从而提高灵活性和可用性。
良好的集成支持:与Quarkus和Spring Boot等流行框架的集成,使得在现有Java项目中引入LLM变得更加简单。

入门示例:集成通义模型
本示例展示了如何通过低级 API 接入阿里百炼平台的通义模型 qwen-turbo。通过使用 LangChain4j 框架,开发者可以轻松调用该模型并集成到 Java 应用中。
Maven 依赖配置
首先,需要在项目中引入以下 Maven 依赖,用于集成 LangChain4j 与 DashScope:
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai-spring-boot-starter</artifactId>
</dependency>
<!-- 加载bom 后,所有langchain4j引用不需要加版本号 -->
<dependencyManagement>
<dependencies>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-bom</artifactId>
<version>0.36.2</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
YML 配置文件
在项目的 application.yml 中设置所使用的通义模型 qwen-turbo,以下是示例配置:
langchain4j:
open-ai:
chat-model:
# 课程测试 KEY,需要更换为实际可用 KEY
api-key: sk-xx
model-name: qwen-turbo
# 百炼兼容OpenAI接口规范,base_url为https://dashscope.aliyuncs.com/compatible-mode/v1
base-url: https://dashscope.aliyuncs.com/compatible-mode/v1
代码实现
使用以下代码,快速启动一个基于 LangChain4j 和 Spring Boot 的 Java 应用,集成并调用阿里百炼平台的通义大语言模型。
package com.pig4cloud.ai.simple;
import dev.langchain4j.model.chat.ChatLanguageModel;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
/**
* 用于处理与通义模型的交互请求测试。
* 作者: lengleng
*/
@SpringBootTest
class SimplechatApplicationTest {
@Autowired
private ChatLanguageModel chatLanguageModel;
@Test
public void testChat(){
String generate = chatLanguageModel.generate("你好");
System.out.println(generate);
}
}
总结
通过引入上述依赖、配置和代码,你可以快速启动并集成阿里百炼平台的通义大语言模型 qwen-turbo。这种方式不仅便于开发者接入大型语言模型,也为项目的智能化提供了极大的便利和扩展性。
Chat API 上手
在这篇文章中,我们将深入了解LangChain4j框架的高层API(AiServices),并展示如何将其与OpenAI集成,以实现简单的聊天功能。我们将讨论LangChain4j支持的各种大型语言模型(LLMs),并逐步展示如何通过示例代码实现。
LangChain4j支持的LLMs
LangChain4j的LLM API概述
核心:ChatLanguageModel 模型元信息提供
1. 依赖包
在pom.xml中添加以下依赖:
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai</artifactId>
</dependency>
2. 配置 ChatLanguageModel 提供模型元信息
@Bean
public ChatLanguageModel chatLanguageModel() {
return OpenAiChatModel.builder()
.apiKey(System.getenv("DASHSCOPE_KEY"))
.modelName("qwen-turbo")
.baseUrl("https://dashscope.aliyuncs.com/compatible-mode/v1")
.build();
}
低级LLM API 调用
使用ChatLanguageModel接口与大模型进行交互。以下是接口的主要方法:
public interface ChatLanguageModel {
String generate(String userMessage);
Response<AiMessage> generate(List<ChatMessage> messages);
}
@SpringBootTest
class SimplechatApplicationTest {
@Autowired
private ChatLanguageModel chatLanguageModel;
@Test
public void testChat(){
String generate = chatLanguageModel.generate("你好");
System.out.println(generate);
}
}
高级LLM API
为了简化开发,LangChain4j提供了高层API,使开发者能够更专注于业务逻辑,而无需关注底层实现细节。高层API中,AiService 用于定义一个集成大模型的服务。
1. 定义AI Service
package com.pig4cloud.ai.service;
/**
* AI 助手接口
*/
public interface ChatAssistant {
String chat(String userMessage);
}
声明成 Spring Bean, 注入模型
@Bean
public ChatAssistant chatAssistant() {
return AiServices.builder(ChatAssistant.class)
.chatLanguageModel(chatLanguageModel())
.build();
}
2. 测试
@SpringBootTest
class ChatAssistantTest {
@Autowired
private ChatAssistant chatAssistant;
@Test
public void testChat() {
String message = "Hello";
String response = chatAssistant.chat(message);
System.out.println(response);
}
}API 进阶配置
1. 日志配置 (Logging)
LangChain4j 使用 SLF4J 作为日志接口,支持集成各种日志后端,如 Logback 或 Log4j。
纯 Java 环境
要启用对每个请求和响应的日志记录,可以在创建模型实例时通过以下方式设置:
OpenAiChatModel.builder()
...
.logRequests(true) // 启用请求日志
.logResponses(true) // 启用响应日志
.build();
确保在依赖项中包含 SLF4J 的日志后端,比如 Logback
Spring Boot 环境
在 Spring Boot 集成中,可以通过 application.properties 文件配置日志级别:
只有日志级别调整为debug级别,同时配置以上 langchain 日志输出开关才有效
logging:
level:
root: debug
2. 监控 (Observability)
LangChain4j 提供了一些语言模型(如 ChatLanguageModel 和 StreamingChatLanguageModel),支持通过 ChatModelListener 监听以下事件:
请求到达 LLM
LLM 返回的响应
错误处理
事件监听的例子如下:
ChatModelListener listener = new ChatModelListener() {
@Override
public void onRequest(ChatModelRequestContext requestContext) {
ChatModelRequest request = requestContext.request();
Map<Object, Object> attributes = requestContext.attributes();
// 记录请求
}
@Override
public void onResponse(ChatModelResponseContext responseContext) {
ChatModelResponse response = responseContext.response();
ChatModelRequest request = responseContext.request();
Map<Object, Object> attributes = responseContext.attributes();
// 记录响应
}
@Override
public void onError(ChatModelErrorContext errorContext) {
Throwable error = errorContext.error();
ChatModelRequest request = errorContext.request();
ChatModelResponse partialResponse = errorContext.partialResponse();
Map<Object, Object> attributes = errorContext.attributes();
// 记录错误
}
};
ChatLanguageModel model = OpenAiChatModel.builder()
...
.listeners(List.of(listener)) // 添加监听器
.build();
3. 重试机制 (Retry Configuration)
LangChain4j 支持重试配置,可用于处理失败的请求。
可以通过 maxRetries 来配置重试逻辑,指定重试次数和延迟等参数:
ChatLanguageModel model = OpenAiChatModel.builder()
...
.maxRetries(5) // 设置重试策略
.build();
4. 超时配置 (Timeout Configuration)
对于超时配置,可以通过 timeout 设置请求的超时时间:
ChatLanguageModel model = OpenAiChatModel.builder()
...
.timeout(Duration.ofSeconds(10)) // 设置10秒超时
.build();Chat 流式输出
LangChain4J 是一个强大的库,专门用于与语言学习模型(LLMs)进行交互。其核心功能之一是能够逐个令牌地流式传输来自 LLMs 的响应。这项功能极大地提升了用户体验,使用户可以在模型生成完整响应前,实时获取部分信息。
本文将详细介绍如何使用 LangChain4J 实现流式聊天功能。
流式响应处理
StreamingResponseHandler 接口
流式响应的关键接口是 StreamingResponseHandler。它允许开发者定义在响应生成过程中的各个事件的处理逻辑。
public interface StreamingResponseHandler<T> {
void onNext(String token);
default void onComplete(Response<T> response) {}
void onError(Throwable error);
}
事件说明
onNext(String token):每当生成下一个令牌时触发,通常用于将实时生成的内容及时反馈给前端。
onComplete(Response response):当模型生成完成时触发。此时返回一个完整的
Response对象。对于StreamingChatLanguageModel,T为AiMessage;对于StreamingLanguageModel,T为String。onError(Throwable error):当生成过程中发生错误时触发。
实现流式聊天的基本示例
以下是使用 StreamingChatLanguageModel 实现流式处理的示例:
StreamingChatLanguageModel model = OpenAiStreamingChatModel.builder()
...
.build();
String userMessage = "讲个笑话";
model.generate(userMessage, new StreamingResponseHandler<AiMessage>() {
@Override
public void onNext(String token) {
System.out.println("onNext: " + token);
}
@Override
public void onComplete(Response<AiMessage> response) {
System.out.println("onComplete: " + response);
}
@Override
public void onError(Throwable error) {
error.printStackTrace();
}
});
示例说明
模型初始化:通过
OpenAiStreamingChatModel.builder()创建一个流式模型实例,并从环境变量中获取 API 密钥。用户输入:定义用户输入消息,此处为”讲个笑话”。
处理响应:传递实现了
StreamingResponseHandler的匿名类,分别定义onNext、onComplete和onError的处理逻辑。
使用 TokenStream 进行流式处理
除了 StreamingResponseHandler,您还可以使用 TokenStream 逐个令牌流式处理响应。
示例代码
interface Assistant {
TokenStream chat(String message);
}
StreamingChatLanguageModel model = OpenAiStreamingChatModel.builder()
...
.build();
Assistant assistant = AiServices.create(Assistant.class, model);
TokenStream tokenStream = assistant.chat("讲个笑话");
tokenStream.onNext(System.out::println)
.onComplete(System.out::println)
.onError(Throwable::printStackTrace)
.start();
示例说明
接口定义:
Assistant接口定义了chat方法,该方法返回TokenStream。模型初始化:同样地,通过
OpenAiStreamingChatModel.builder()初始化模型。TokenStream 处理:对返回的
TokenStream进行订阅,分别处理onNext、onComplete和onError事件,并启动流式处理。
使用 Flux 进行流式处理
除了 TokenStream,您还可以通过 Reactor 库中的 Flux<String> 实现响应流式传输。为此,您需要引入 langchain4j-reactor 依赖。
Maven 依赖
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-reactor</artifactId>
<version>0.35.0</version>
</dependency>
示例代码
interface Assistant {
Flux<String> chat(String message);
}
StreamingChatLanguageModel model = OpenAiStreamingChatModel.builder()
...
.build();
Assistant assistant = AiServices.create(Assistant.class, model);
Flux<String> tokenFlux = assistant.chat("讲个笑话");
tokenFlux.subscribe(
System.out::println, // onNext
Throwable::printStackTrace, // onError
() -> System.out.println("onComplete") // onComplete
);
示例说明
接口定义:
Assistant接口定义了返回Flux<String>的chat方法。模型初始化:使用与之前相同的方式初始化模型。
订阅处理:使用
Flux.subscribe来处理每个生成的令牌、错误和完成事件。
总结
LangChain4J 提供了一种高效且灵活的方式来流式传输语言模型的响应。通过 StreamingResponseHandler、TokenStream 或 Flux,开发者可以实现流畅的实时响应体验,从而提升应用的互动性和响应速度。
流式处理让用户无需等待完整响应生成即可获取部分内容,尤其适用于聊天机器人和交互式 AI 应用的开发。
Chat 视觉理解
示例代码:基于Dashscope的LangChain4j视觉理解
这个示例展示了如何通过Dashscope的API,结合LangChain4j进行图像理解。使用的模型是qwen-vl-max,其支持视觉-语言的多模态任务。
从非规则图片中读取指定日期的指数点数

构建大模型客户端
@Bean
public ChatLanguageModel chatLanguageModel() {
return OpenAiChatModel.builder()
.apiKey(System.getenv("DASHSCOPE_KEY"))
.modelName("qwen-vl-max") // 设置使用的模型名称
.baseUrl("https://dashscope.aliyuncs.com/compatible-mode/v1")
.build();
}
构建 ImageContent
/**
* 作者: lengleng
* 视觉理解示例 - 通过Dashscope进行图像分析
*/
@SpringBootTest
class LLMConfigTest {
@Autowired
private ChatLanguageModel chatLanguageModel;
@Value("1.png")
private Resource resource;
@Test
void chatLanguageModel() throws IOException {
byte[] byteArray = resource.getContentAsByteArray();
String encodeToString = Base64.getEncoder().encodeToString(byteArray);
UserMessage userMessage = UserMessage.from(
TextContent.from("提取图片中 9月30号的上证指数点数")
,
ImageContent.from(encodeToString, "image/png")
);
Response<AiMessage> response = chatLanguageModel.generate(userMessage);
System.out.println(response.content().text());
}
}
说明:
模型选择:
qwen-vl-max是一个多模态大模型,支持图片和文本的结合输入,适用于视觉-语言任务。图片上传:通过
Base64编码将图片转化为字符串,结合ImageContent和TextContent一起发送到模型进行处理。API调用:使用
OpenAiChatModel来构建请求,并通过chat()方法调用模型。请求内容包括文本提示和图片,模型会根据输入返回分析结果。解析与输出:从
ChatResponse中获取AI的回复,打印出处理后的结果。
应用场景:
图像文字提取:如发票信息的提取、表单中的数据信息识别等。
图像标注和理解:结合文本输入,根据特定位置或内容要求对图像进行详细分析。
这种方法可以应用在实际业务中,如OCR(光学字符识别)、图像审核、合规性检查等。
Chat 记忆缓存

记忆缓存是聊天系统中的一个重要组件,用于存储和管理对话的上下文信息。它的主要作用是让AI助手能够”记住”之前的对话内容,从而提供连贯和个性化的回复。
1. 简介
ChatMemory是一个用于管理聊天上下文的组件,它可以解决以下问题:
防止上下文超出大模型的token限制
隔离不同用户的上下文信息
简化ChatMessage的管理

2. 核心功能
容器管理: 管理ChatMessage的生命周期
淘汰机制: 防止存储过多消息
持久化: 避免聊天上下文丢失
3. ChatMemory实现类
LangChain4j提供了两种主要的ChatMemory实现类,每种都有其特定的用途和优势:
3.1 MessageWindowChatMemory(简单实现)
这是一个基于消息数量的简单实现。它采用滑动窗口的方式,保留最新的N条消息,并淘汰旧消息。
特点:
易于理解和实现
基于消息数量进行管理
适用于不需要精确token控制的场景
使用示例:
ChatMemory chatMemory = MessageWindowChatMemory.withMaxMessages(10);
3.2 TokenWindowChatMemory(复杂实现)
这是一个更复杂的实现,它同样采用滑动窗口的方式,但侧重于保留最新的tokens,而不是消息数量。
特点:
更精确的token控制
需要结合Tokenizer计算ChatMessage的token数量
适用于需要严格控制token使用的场景
使用示例:
Tokenizer tokenizer = new OpenAiTokenizer(GPT_3_5_TURBO);
ChatMemory chatMemory = TokenWindowChatMemory.withMaxTokens(1000, tokenizer);
注意: 使用TokenWindowChatMemory需要提供一个Tokenizer实例,用于计算消息的token数量。不同的语言模型可能需要不同的Tokenizer。
4. 实现方式
4.0 Ai Services 定义
public interface ChatAssistant {
/**
* 聊天
*
* @param message 消息
* @return {@link String }
*/
String chat(String message);
/**
* 聊天
*
* @param userId 用户 ID (根据ID隔离记忆)
* @param message 消息
* @return {@link String }
*/
String chat(@MemoryId Long userId, @UserMessage String message);
}
4.1 共享ChatMemory
适用于单用户场景。
ChatMemory chatMemory = MessageWindowChatMemory.withMaxMessages(10);
ChatAssistant assistant = AiServices.builder(ChatAssistant.class)
.chatLanguageModel(chatLanguageModel)
.chatMemory(chatMemory)
.build();
String answer1 = assistant.chat("你好!我的名字是冷冷.");
String answer2 = assistant.chat("我的名字是什么?");
4.2 独享ChatMemory
适用于多用户场景。
ChatAssistant assistant = AiServices.builder(ChatAssistant.class)
.chatLanguageModel(chatLanguageModel)
// 注意每个memoryId对应创建一个ChatMemory
.chatMemoryProvider(memoryId -> MessageWindowChatMemory.withMaxMessages(10))
.build();
assistant.chat(1L, "你好!我的名字是冷冷1.");
assistant.chat(2L, "你好!我的名字是冷冷2.");
String chat = assistant.chat(1L, "我的名字是什么");
System.out.println(chat);
chat = assistant.chat(2L, "我的名字是什么");
System.out.println(chat);
5. 自定义持久化
如需自定义持久化方式,可以实现ChatMemoryStore接口:
public class PersistentChatMemoryStore implements ChatMemoryStore {
private final DB db = DBMaker.fileDB("./chat-memory.db").transactionEnable().make();
private final Map<Integer, String> map = db.hashMap("messages", INTEGER, STRING).createOrOpen();
@Override
public List<ChatMessage> getMessages(Object memoryId) {
String json = map.get((int) memoryId);
return messagesFromJson(json);
}
@Override
public void updateMessages(Object memoryId, List<ChatMessage> messages) {
String json = messagesToJson(messages);
map.put((int) memoryId, json);
db.commit();
}
@Override
public void deleteMessages(Object memoryId) {
map.remove((int) memoryId);
db.commit();
}
}
6. 注意事项
SystemMessage会被特殊处理,始终保留且只允许一个
工具消息(如函数调用)需要成对处理
默认实现是基于内存的,如需持久化需自行实现
7. 最佳实践
根据实际需求选择共享或独享ChatMemory
合理选择ChatMemory实现类:
对于简单场景,使用MessageWindowChatMemory
对于需要精确控制token的场景,使用TokenWindowChatMemory
合理设置消息窗口大小或token限制,平衡上下文信息和性能
针对多用户场景,使用独享ChatMemory并提供唯一的memoryId
如有持久化需求,自定义实现ChatMemoryStore接口
注意处理特殊消息类型,如SystemMessage和工具消息
通过合理使用ChatMemory,可以有效管理聊天上下文,提升大模型应用的用户体验和性能。选择合适的ChatMemory实现类和配置可以帮助您在保留必要上下文信息和控制资源使用之间取得平衡。
提示词工程
在本文中,我们将探讨如何利用LangChain4j框架构建一个专业的法律咨询助手。这个助手将专注于回答中国法律相关问题,对其他领域的咨询则会礼貌地拒绝。我们将深入了解角色设定和提示词模板的使用,这是实现这个功能的两个关键要素。
角色设定:塑造AI助手的专业身份
角色设定是指导大语言模型(LLM)行为的重要手段。通过明确定义AI助手的身份和能力范围,我们可以使其更专注于特定领域的任务。在LangChain4j中,我们主要利用SystemMessage来实现这一点。
SystemMessage具有高优先级,能有效地指导模型的整体行为。例如,我们可以这样定义一个专业法律顾问的角色:
@SystemMessage("你是一位专业的中国法律顾问,只回答与中国法律相关的问题。输出限制:对于其他领域的问题禁止回答,直接返回'抱歉,我只能回答中国法律相关的问题。'")
提示词模板:精确控制输入输出
LangChain4j提供了多种方式来使用提示词模板,让我们能够灵活地构造输入并控制输出。以下是几种常用的方法:
1. 使用 @UserMessage 和 @V 注解:
public interface AiAssistant {
@SystemMessage("你是一位专业的中国法律顾问,只回答与中国法律相关的问题。输出限制:对于其他领域的问题禁止回答,直接返回'抱歉,我只能回答中国法律相关的问题。'")
@UserMessage("请回答以下法律问题:{{question}}")
String answerLegalQuestion(@V("question") String question);
}
2. 使用 @StructuredPrompt 定义结构化提示:
@Data
@StructuredPrompt("根据中国{{legal}}法律,解答以下问题:{{question}}")
class LegalPrompt {
private String legal;
private String question;
}
public interface AiAssistant {
@SystemMessage("你是一位专业的中国法律顾问,只回答与中国法律相关的问题。输出限制:对于其他领域的问题禁止回答,直接返回'抱歉,我只能回答中国法律相关的问题。'")
String answerLegalQuestion(LegalPrompt prompt);
}
3. 使用 PromptTemplate 渲染:
// 默认 form 构造使用 it 属性作为默认占位符
PromptTemplate template = PromptTemplate.from("请解释中国法律中的'{{it}}'概念。");
Prompt prompt = template.apply("知识产权");
System.out.println(prompt.text()); // 输出: 请解释中国法律中的'知识产权'概念。
// apply 方法接受 Map 作为参数
PromptTemplate template2 = PromptTemplate.from("请解释中国法律中的'{{legal}}'概念。");
Prompt prompt2 = template2.apply(Map.of("legal", "知识产权"));
System.out.println(prompt2.text());
实现专业法律咨询助手
现在,让我们来实现这个专业的法律咨询助手。
1. 定义 LegalAdvisor 接口:
@AiService
public interface LegalAssistant {
@SystemMessage("你是一位专业的中国法律顾问,只回答与中国法律相关的问题。对于其他领域的问题,请回复'抱歉,我只能回答中国法律相关的问题。'")
@UserMessage("请回答以下法律问题:{{question}}")
String answerLegalQuestion(@V("question") String question);
}
2. 创建一个控制器来处理法律咨询请求:
/**
* 法律咨询控制器
*
* @author lengleng
*/
@RestController
public class LegalAdvisorController {
@Autowired
private LegalAssistant legalAssistant;
@GetMapping("/legal")
public String getLegalAdvice(@RequestParam("question") String question) {
return legalAssistant.answerLegalQuestion(question);
}
}
测试与效果
使用这个法律咨询助手,我们可以得到以下效果:
法律相关问题: 输入: “什么是著作权?” 输出: “著作权是指作者对其创作的文学、艺术和科学作品所享有的专有权利。在中国,著作权自作品创作完成之日起自动产生,无需注册。它包括发表权、署名权、修改权、保护作品完整权等人身权利,以及复制权、发行权、出租权、展览权、表演权、放映权、广播权、信息网络传播权、摄制权、改编权、翻译权和汇编权等财产权利。著作权的保护期通常是作者终生加死后50年。”
非法律问题: 输入: “请介绍一下人工智能技术” 输出: “抱歉,我只能回答中国法律相关的问题。“
总结
通过LangChain4j框架,我们成功实现了一个专注于中国法律咨询的AI助手。关键点在于:
使用
SystemMessage明确定义助手的角色和能力范围,将其限定在法律咨询领域。利用提示词模板(
@UserMessage,@V)精确控制输入和期望的输出格式,确保问题被正确理解和回答。在接口中组合使用这些注解,轻松实现复杂的AI交互逻辑,使助手能够识别并回应法律相关问题。
这个例子展示了LangChain4j在构建专业化AI应用方面的强大功能和灵活性。通过合理设置角色和精心设计提示词,我们可以创建出专注于特定领域(如法律咨询)的AI助手,为用户提供准确、相关的信息和建议。这种方法不仅提高了AI助手的实用性,还确保了其在专业领域内的可靠性和专业性。
JSON 结构化输出
在与大语言模型(LLM)交互时,我们常常需要将其输出转换为结构化的数据格式,以便进一步处理和使用。LangChain4j框架为我们提供了一种优雅的方式来实现这一目标。本文将深入探讨LangChain4j如何将LLM的返回结果格式化为各种数据类型,包括基本类型、集合、自定义POJO等。
LangChain4j支持的返回类型
结构化输出示例
让我们通过一些具体的例子来看看如何使用LangChain4j处理不同类型的输出。
布尔值与枚举
package com.pig4cloud.ai.sentiment;
import dev.langchain4j.service.UserMessage;
import dev.langchain4j.service.spring.AiService;
public interface SentimentAnalyzer {
// text=假期结束开始上班
@UserMessage("{{it}} 是否具有正面情感?")
boolean isPositive(String text);
// text=假期结束开始上班
@UserMessage("分析 {{it}} 的情感")
Sentiment analyzeSentimentOf(String text);
enum Sentiment {
POSITIVE, // 正面情感
NEGATIVE, // 负面情感
NEUTRAL // 中立情感
}
}
在这个例子中,我们定义了一个SentimentAnalyzer接口,它使用LangChain4j的@AiService和@UserMessage注解来处理情感分析任务。该接口包含两个方法:
isPositive: 返回布尔值,表示文本是否具有积极情感。analyzeSentimentOf: 返回枚举值,表示文本的情感倾向(积极、消极或中性)。
数字类型
对于数字类型的处理,LangChain4j同样提供了强大的支持:
public interface NumberExtractor {
// text=我赚了100块
@UserMessage("Extract a number from {{it}}")
int extractInt(String text);
// text=我赚了100块
@UserMessage("Extract a long number from {{it}}")
long extractLong(String text);
// text=我赚了100块
@UserMessage("Extract a big integer from {{it}}")
BigInteger extractBigInteger(String text);
// text=我赚了100块
@UserMessage("Extract a float number from {{it}}")
float extractFloat(String text);
// text=我赚了100块
@UserMessage("Extract a double number from {{it}}")
double extractDouble(String text);
// text=我赚了100块
@UserMessage("Extract a big decimal from {{it}}")
BigDecimal extractBigDecimal(String text);
}
这个NumberExtractor接口展示了如何从文本中提取各种数值类型,包括整数、长整数、大整数、浮点数、双精度浮点数和大小数。
自定义POJO
LangChain4j还支持将LLM输出解析为自定义的POJO对象:
@AiService
public interface PersonExtractor {
@UserMessage("Extract information about a person from {{it}}")
Person extractPerson(String text);
@Data
class Person {
@Description("name of a person") // 增加字段描述,让大模型更理解字段含义
private String name;
private LocalDate birthDate;
}
}
在这个例子中,我们定义了一个Person类作为自定义POJO,包含name 和birthDate字段。extractPerson方法将从给定文本中提取人物信息并返回一个Person对象。
通过掌握这些核心组件,我们就能更好地利用LangChain4j来处理大语言模型的结构化输出,为我们的AI应用开发带来更多可能性。
函数调用
在人工智能的世界里,大语言模型(LLMs)不仅仅是文本生成的能手,它们还能触发实际的操作。这种能力,我们称之为函数调用或函数调用。本文将深入探讨 LangChain4j 框架是如何实现这一强大功能的。
函数调用:LLM 的得力助手
函数调用让 LLM 能够根据输入的提示,生成一个调用特定函数的请求。这个请求包含了函数名称和所需的参数信息。通过这种方式,我们可以将 LLM 的智能与外部工具或 API 无缝连接。
举个例子,众所周知,LLM 在复杂数学计算方面并不擅长。如果您的应用场景涉及大量数学运算,您可以为 LLM 提供一个”数学工具”。LLM 会根据工具的描述,返回需要调用的函数名称和参数。然后,您的系统执行该函数,获取结果,再将结果和原始提示一起发送给 LLM,最终得到综合的回答。
重要提示: LLM 本身并不执行函数,它只是指示应该调用哪个函数以及如何调用。
函数调用的应用场景
触发外部操作:如发送邮件、控制智能家居设备等。
实时数据获取:解决 LLM 知识更新滞后的问题,如进行实时搜索或数据库查询。
复杂逻辑处理:处理 LLM 难以直接计算的复杂数据运算问题。

编码注入函数
public interface FunctionAssistant {
String chat(String message);
}
工具说明 ToolSpecification
业务逻辑 ToolExecutor
@Bean
public FunctionAssistant functionAssistant(ChatLanguageModel chatLanguageModel) {
// 工具说明 ToolSpecification
ToolSpecification toolSpecification = ToolSpecification.builder()
.name("invoice_assistant")
.description("根据用户提交的开票信息,开具发票")
.addParameter("companyName", type("string"), description("公司名称"))
.addParameter("dutyNumber", type("string"), description("税号"))
.addParameter("amount", type("number"), description("金额"))
.build();
// 业务逻辑 ToolExecutor
ToolExecutor toolExecutor = (toolExecutionRequest, memoryId) -> {
String arguments1 = toolExecutionRequest.arguments();
System.out.println("arguments1 =>>>> " + arguments1);
return "开具成功";
};
return AiServices.builder(FunctionAssistant.class)
.chatLanguageModel(chatLanguageModel)
.tools(Map.of(toolSpecification, toolExecutor))
.build();
}
注解注入函数
通过使用注解 @Tool,可以更方便地集成函数调用。LangChain4j 的 AI 服务会自动处理工具执行,无需手动管理工具请求。
工具定义:只需将Java方法标注为 @Tool,LangChain4j 就会自动将其转换为 ToolSpecification,并且在与LLM交互时调用这些方法。
@Slf4j
public class InvoiceHandler {
@Tool("根据用户提交的开票信息进行开票")
public String handle(String companyName, String dutyNumber,@P("金额保留两位有效数字") String amount) {
log.info("companyName =>>>> {} dutyNumber =>>>> {} amount =>>>> {}", companyName, dutyNumber, amount);
return "开票成功";
}
}
@Bean
public FunctionAssistant functionAssistant(ChatLanguageModel chatLanguageModel) {
return AiServices.builder(FunctionAssistant.class)
.chatLanguageModel(chatLanguageModel)
.tools(new InvoiceHandler())
.build();
}
动态工具配置
LangChain4j 支持动态工具配置,开发者可以基于用户输入的上下文,在运行时动态加载工具。通过 ToolProvider 接口,工具集会在每次请求时动态生成。
例如,只有当用户提到 “booking” 时才加载相关的工具:
ToolProvider toolProvider = (toolProviderRequest) -> {
if (toolProviderRequest.userMessage().singleText().contains("booking")) {
ToolSpecification toolSpecification = ToolSpecification.builder()
.name("get_booking_details")
.description("Returns booking details")
.addParameter("bookingNumber", type("string"))
.build();
return ToolProviderResult.builder()
.add(toolSpecification, toolExecutor)
.build();
} else {
return null;
}
};
小结
函数调用为LLM增加了扩展性,使其能够与外部世界互动,实现更复杂的任务。通过LangChain4j的低级和高级API,开发者可以灵活地集成和管理这些工具,从而创建智能化、自动化的应用场景。
这种灵活的架构,结合了对具体任务的自动化调用,能大大增强LLM的实用性,尤其适用于需要集成外部API、进行计算或其他任务的应用。
动态函数调用
引言
在现代软件开发中,代码执行引擎的应用场景日益广泛。LangChain4j框架通过集成多种代码执行引擎,为开发者提供了强大的工具支持。本文将详细介绍LangChain4j如何接入GraalVM,实现动态函数调用,并探讨其在实际业务场景中的应用。
代码执行引擎的使用场景
在大模型执行function calling的流程中:
大模型首先返回可直接运行的脚本语言代码
LangChain4j接收到这段可运行代码后,调用
CodeExecutionEngine执行执行结果返回给大模型
LangChain4j支持的执行引擎
LangChain4j目前支持两种主要的代码执行引擎:
GraalVM
Polyglot: 允许在同一应用中无缝使用多种编程语言
Truffle: 用于构建语言引擎的框架,支持轻松添加新语言
Judge0
开源代码执行引擎,支持多种编程语言(C, C++, Java, Python, Ruby等)
被誉为”世界上最先进的开源在线代码执行系统”
执行引擎测试
1. 添加依赖
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-code-execution-engine-graalvm-polyglot</artifactId>
</dependency>
2. 调用 js 版本斐波那契数列
CodeExecutionEngine engine = new GraalVmJavaScriptExecutionEngine();
String code = """
function fibonacci(n) {
if (n <= 1) return n;
return fibonacci(n - 1) + fibonacci(n - 2);
}
fibonacci(10)
""";
String result = engine.execute(code);
动态函数示例
1. 配置类
ChatAssistant assistant = AiServices.builder(ChatAssistant.class)
.chatLanguageModel(chatLanguageModel)
.tools(new GraalVmJavaScriptExecutionTool())
.build();
2. AI Service 定义
public interface Assistant {
String chat(String message);
}
3. 测试
String chat = chatAssistant.chat("What is the square root of 485906798473894056 in scientific notation?");
System.out.println(chat);
实现原理
LangChain4j通过GraalVmJavaScriptExecutionTool类实现了JavaScript代码的动态执行。以下是该类的核心实现:
public class GraalVmJavaScriptExecutionTool {
// 初始化一个GraalVM JavaScript执行引擎
private final CodeExecutionEngine engine = new GraalVmJavaScriptExecutionEngine();
/**
* 执行JavaScript代码的方法
*
* @Tool 注解标记这个方法为一个工具,可以被AI助手调用
* 描述指定了这个工具必须用于精确计算,如数学运算、排序、过滤、聚合、字符串处理等
*/
@Tool("MUST be used for accurate calculations: math, sorting, filtering, aggregating, string processing, etc")
public String executeJavaScriptCode(
// @P 注解用于描述参数
// 这里说明输入的JavaScript代码必须返回一个结果
@P("JavaScript code to execute, result MUST be returned by the code") String code
) {
// 调用GraalVM执行引擎来执行传入的JavaScript代码
return engine.execute(code);
}
}
这个类的主要功能包括:
封装GraalVM JavaScript执行引擎
提供一个被
@Tool注解标记的方法,可以被AI助手调用接受JavaScript代码作为输入,执行代码并返回结果
通过这种方式,LangChain4j能够在运行时动态执行JavaScript代码,为AI助手提供强大的计算和数据处理能力。
优势与局限性
优势:
灵活性:允许AI助手执行动态生成的代码,大大增强了系统的适应性
性能:GraalVM提供了高效的代码执行能力
多语言支持:GraalVM的Polyglot特性使得未来可以轻松扩展到其他编程语言
局限性:
安全性考虑:动态执行代码可能带来安全风险,需要严格的代码审查和沙箱机制
复杂性:集成GraalVM可能增加系统的复杂性
资源消耗:动态编译和执行可能增加系统资源消耗
结论
LangChain4j通过接入GraalVM实现的动态函数调用功能,为AI系统提供了强大的计算能力和灵活性。这种方法使得AI助手能够执行复杂的操作,大大扩展了其应用范围。然而,在实际应用中,开发者需要权衡其优势和潜在的风险,确保系统的安全性和稳定性。
未来,随着技术的不断发展,我们可以期待看到更多创新的代码执行方案,进一步推动AI系统的进步。
函数增强搜索
SearchApi 是一个实时搜索引擎结果页面(SERP)API。你可以使用它进行 Google、Google News、Bing、Bing News、Baidu、Google Scholar 等搜索引擎的查询,获取有机搜索结果。

使用方法
获取 API KEY
依赖配置
在你的项目 pom.xml 中添加以下依赖:
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-web-search-engine-searchapi</artifactId>
</dependency>
定义 Ai Service
public interface ChatAssistant {
@SystemMessage("""
1. 搜索支持:你的职责是为用户提供基于网络搜索的支持。
2. 事件验证:如果用户提到的事件尚未发生或信息不明确,你需要通过网络搜索确认或查找相关信息。
3. 网络搜索请求:使用用户的查询创建网络搜索请求,并通过网络搜索工具进行实际查询。
4. 引用来源:在最终回应中,必须包括搜索到的来源链接,以确保信息的准确性和可验证性。
""")
String chat(String message);
}
注入 web search
@Bean
public ChatAssistant chatAssistant(ChatLanguageModel chatLanguageModel) {
SearchApiWebSearchEngine searchEngine = SearchApiWebSearchEngine.builder()
.apiKey("p8SZVNAweqTtoZBBTVnXttcj")// 测试使用
.engine("google")
.build();
WebSearchTool webSearchTool = WebSearchTool.from(searchEngine);
return AiServices.builder(ChatAssistant.class).chatLanguageModel(chatLanguageModel).tools(webSearchTool).build();
}
测试
String chat = chatAssistant.chat("20241008 上证指数是多少");
System.out.println(chat);
截至2024年10月8日,A股市场迎来了国庆节后的首个交易日,主要指数表现强劲。具体到上证指数,开盘时涨幅达到了10.13%,但之后的走势有所调整,最终收盘时上证指数报收于3489.78点,涨幅为4.59%。这一天,沪深两市的成交额均非常活跃,接近或超过3.5万亿元人民币。
以上信息来源于多个新闻源,包括财新网、观察者网、中国新闻网、新浪财经等,您可以点击提供的链接查看更详细的信息和报道背景。请注意,这些数据和分析仅供参考,市场情况可能会随时变化。
Langchain4j 支持的搜索引擎
任何返回 organic_results 数组的搜索引擎都可以被此库支持,即使不在上述列表中,只要有 title、link 和 snippet 字段的有机搜索结果。
向量化及存储
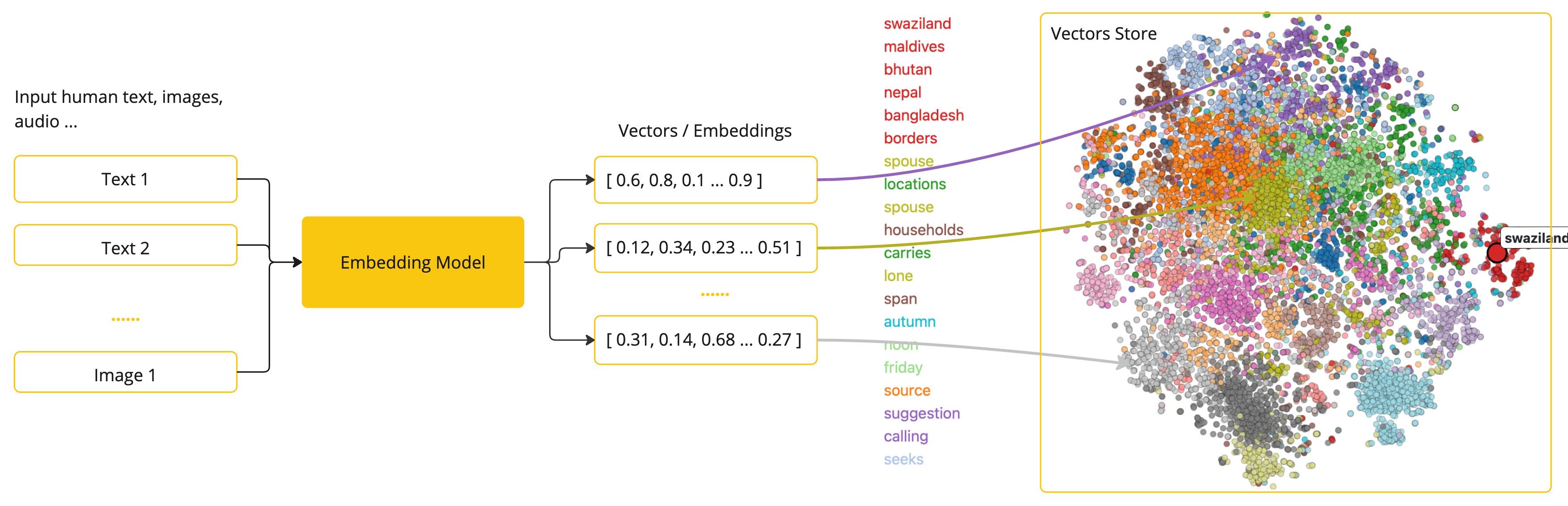
Embedding模型简介
Embedding模型是将文本数据(如词汇、短语或句子)转换为数值向量的工具,这些向量捕捉了文本的语义信息,可用于各种自然语言处理(NLP)任务。
工作原理
Embedding模型将文本映射到高维空间中的点,使语义相似的文本在这个空间中距离较近。例如,“猫”和”狗”的向量可能会比”猫”和”汽车”的向量更接近。
优点
捕捉复杂的词汇关系(如语义相似性、同义词、多义词)
超越传统词袋模型的简单计数方式
动态嵌入模型(如BERT)可根据上下文生成不同的词向量
LangChain支持的向量数据库
LangChain支持多种向量数据库,每种数据库具有不同的特性。以下是部分支持的向量数据库及其功能:
文本向量化
使用OpenAI的Embedding模型进行文本向量化的示例代码:
Qdrant向量库存储
Qdrant是一个高性能的向量数据库,用于存储嵌入并进行快速的向量搜索。
安装Qdrant
使用Docker安装Qdrant:
docker run -p 6333:6333 -p 6334:6334 qdrant/qdrant
端口6333:用于HTTP API
端口6334:用于gRPC API
集成LangChain4j与Qdrant
添加Maven依赖:
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-qdrant</artifactId>
</dependency>
创建Qdrant客户端:
@Bean
public QdrantClient qdrantClient() {
QdrantGrpcClient.Builder grpcClientBuilder = QdrantGrpcClient.newBuilder("127.0.0.1", 6334, false);
return new QdrantClient(grpcClientBuilder.build());
}
创建索引:
var vectorParams = Collections.VectorParams.newBuilder()
.setDistance(Collections.Distance.Cosine)
.setSize(1024)
.build();
qdrantClient.createCollectionAsync("testv", vectorParams);
配置Qdrant Embedding Store:
@Bean
public EmbeddingStore<TextSegment> embeddingStore() {
return QdrantEmbeddingStore.builder()
.host("127.0.0.1")
.port(6334)
.collectionName("testv")
.build();
}
文本生成与存储:
TextSegment segment1 = TextSegment.from("浏览器报错 404,请检测您输入的路径是否正确");
segment1.metadata().put("author", "冷冷");
Embedding embedding1 = embeddingModel.embed(segment1).content();
embeddingStore.add(embedding1, segment1);
向量查询与过滤
基本向量查询:
Embedding queryEmbedding = embeddingModel.embed("404 是哪里的问题?").content();
EmbeddingSearchRequest embeddingSearchRequest = EmbeddingSearchRequest.builder()
.queryEmbedding(queryEmbedding)
.maxResults(1)
.build();
EmbeddingSearchResult<TextSegment> searchResult = embeddingStore.search(embeddingSearchRequest);
System.out.println(searchResult.matches().get(0).embedded().text());
带元数据过滤的查询:
EmbeddingSearchRequest embeddingSearchRequest = EmbeddingSearchRequest.builder()
.queryEmbedding(queryEmbedding)
.filter(metadataKey("author").isEqualTo("冷冷"))
.maxResults(1)
.build();
常用过滤器:
输出结果:
List<EmbeddingMatch<TextSegment>> relevant = searchResult.matches();
EmbeddingMatch<TextSegment> embeddingMatch = relevant.get(0);
System.out.println(embeddingMatch.score()); // 输出匹配分数
System.out.println(embeddingMatch.embedded().text()); // 输出匹配文本
结论
本文档详细介绍了Embedding模型的概念、LangChain支持的向量数据库、文本向量化过程,以及如何使用Qdrant向量库进行存储和查询。通过这些步骤,你可以快速搭建基于Qdrant的高效向量搜索系统,为自然语言处理任务提供强大的支持。
文本向量化分类
智慧HR: 基于LangChain4j文本向量的面试者性格特征匹配
性格特征匹配是HR领域的一项重要任务,它通过分析面试者的语言表达、行为模式等信息,将其与预定义的性格标签进行匹配。这有助于HR专业人士更好地评估候选人是否适合特定职位或团队文化。
LangChain4j中的文本分类支持
LangChain4j框架通过TextClassifier接口,结合向量模型,为我们提供了实现性格特征匹配的强大工具。
基于向量模型的分类器实现
EmbeddingModelTextClassifier通过向量模型对文本进行向量化,并利用余弦相似度计算文本与性格标签之间的匹配度。
配置 EmbeddingModel
@Bean
public EmbeddingModel embeddingModel() {
return OpenAiEmbeddingModel.builder()
.apiKey(System.getenv("DASHSCOPE_KEY"))
.modelName("text-embedding-v3")
.baseUrl("https://dashscope.aliyuncs.com/compatible-mode/v1")
.build();
}
定义业务枚举
@Getter
@AllArgsConstructor
public enum PersonalityTrait {
/**
* 外向型:喜欢社交,从与他人互动中获得能量
*/
EXTROVERT,
/**
* 内向型:倾向于独处,需要安静时间来恢复能量
*/
INTROVERT,
/**
* 分析型:擅长逻辑思考,喜欢解决复杂问题
*/
ANALYTICAL,
/**
* 创意型:富有想象力,常有新颖的想法
*/
CREATIVE,
/**
* 领导型:善于指导他人,乐于承担责任
*/
LEADER,
/**
* 团队合作型:重视协作,善于在团队中工作
*/
TEAM_PLAYER
}
配置向量文本分类器
@Bean
public EmbeddingModelTextClassifier<PersonalityTrait> textClassifier(EmbeddingModel embeddingModel) {
return new EmbeddingModelTextClassifier<>(embeddingModel, PersonalityTraitExamples.examples);
}
示例数据
public class PersonalityTraitExamples {
public static final Map<PersonalityTrait, List<String>> examples = Map.of(
PersonalityTrait.EXTROVERT, List.of(
"我喜欢结识新朋友",
"团体活动让我充满活力",
"我经常是聚会的焦点",
"我喜欢在热闹的社交环境中工作"
),
PersonalityTrait.INTROVERT, List.of(
"我更喜欢独自工作",
"我需要安静的时间来充电",
"大型社交聚会让我感到压抑",
"我喜欢深入的一对一谈话"
),
PersonalityTrait.ANALYTICAL, List.of(
"我喜欢解决复杂的问题",
"数据驱动的决策至关重要",
"我总是寻找信息中的模式和联系",
"我倾向于在采取行动之前彻底分析情况"
),
PersonalityTrait.CREATIVE, List.of(
"我常常跳出框架思考",
"我总是想出新的点子",
"我喜欢寻找创新的解决方案",
"我受到周围艺术和美的启发"
),
PersonalityTrait.LEADER, List.of(
"我能自信地领导项目",
"我激励他人实现目标",
"我喜欢指导和培养团队成员",
"我不怕做出艰难的决定"
),
PersonalityTrait.TEAM_PLAYER, List.of(
"合作是成功的关键",
"我重视所有团队成员的意见",
"我总是愿意帮助我的同事",
"我相信团队中多样化视角的力量"
)
);
}
测试
@Autowired
private EmbeddingModelTextClassifier<PersonalityTrait> textClassifier;
@Test
void analyzePersonality() {
List<PersonalityTrait> classify = textClassifier.classify("赠人玫瑰,手有余香");
System.out.println(classify);
}
源码解析
/**
* 基于嵌入模型的文本分类器
* 这个分类器使用嵌入模型来对文本进行分类,通过比较待分类文本的嵌入与每个标签的示例文本嵌入的相似度来实现分类。
*
* @param <E> 标签的枚举类型
*/
public class EmbeddingModelTextClassifier<E extends Enum<E>> implements TextClassifier<E> {
// 用于生成文本嵌入的嵌入模型
private final EmbeddingModel embeddingModel;
// 存储每个标签对应的示例文本嵌入
private final Map<E, List<Embedding>> exampleEmbeddingsByLabel;
// 分类结果返回的最大标签数量
private final int maxResults;
// 分类时的最小相似度得分阈值
private final double minScore;
// 平均得分和最大得分的权重比例
private final double meanToMaxScoreRatio;
/**
* 使用默认参数创建分类器
* maxResults默认为1, minScore默认为0, meanToMaxScoreRatio默认为0.5
*
* @param embeddingModel 用于嵌入示例和待分类文本的嵌入模型
* @param examplesByLabel 每个标签对应的示例文本集合,示例越多效果越好
*/
public EmbeddingModelTextClassifier(EmbeddingModel embeddingModel,
Map<E, ? extends Collection<String>> examplesByLabel) {
this(embeddingModel, examplesByLabel, 1, 0, 0.5);
}
/**
* 创建分类器的完整构造函数
*
* @param embeddingModel 用于嵌入示例和待分类文本的嵌入模型
* @param examplesByLabel 每个标签对应的示例文本集合
* @param maxResults 每次分类返回的最大标签数量
* @param minScore 分类的最小相似度得分阈值,范围[0..1]
* @param meanToMaxScoreRatio 平均得分和最大得分的权重比例,范围[0..1]
* 0表示仅使用平均得分,1表示仅使用最大得分,0.5表示平均和最大得分equally加权
*/
public EmbeddingModelTextClassifier(EmbeddingModel embeddingModel,
Map<E, ? extends Collection<String>> examplesByLabel,
int maxResults,
double minScore,
double meanToMaxScoreRatio) {
// 参数校验
this.embeddingModel = ensureNotNull(embeddingModel, "embeddingModel");
ensureNotNull(examplesByLabel, "examplesByLabel");
// 预计算并存储所有示例文本的嵌入
this.exampleEmbeddingsByLabel = new HashMap<>();
examplesByLabel.forEach((label, examples) ->
exampleEmbeddingsByLabel.put(label, embeddingModel.embedAll(
examples.stream()
.map(TextSegment::from)
.collect(toList())).content()
)
);
// 设置其他参数
this.maxResults = ensureGreaterThanZero(maxResults, "maxResults");
this.minScore = ensureBetween(minScore, 0.0, 1.0, "minScore");
this.meanToMaxScoreRatio = ensureBetween(meanToMaxScoreRatio, 0.0, 1.0, "meanToMaxScoreRatio");
}
/**
* 对给定文本进行分类
*
* @param text 待分类的文本
* @return 分类结果,即最相似的标签列表
*/
@Override
public List<E> classify(String text) {
// 获取待分类文本的嵌入
Embedding textEmbedding = embeddingModel.embed(text).content();
List<LabelWithScore> labelsWithScores = new ArrayList<>();
// 计算待分类文本与每个标签的示例文本的相似度
exampleEmbeddingsByLabel.forEach((label, exampleEmbeddings) -> {
double meanScore = 0;
double maxScore = 0;
// 计算与每个示例的相似度
for (Embedding exampleEmbedding : exampleEmbeddings) {
double cosineSimilarity = CosineSimilarity.between(textEmbedding, exampleEmbedding);
double score = RelevanceScore.fromCosineSimilarity(cosineSimilarity);
meanScore += score;
maxScore = Math.max(score, maxScore);
}
meanScore /= exampleEmbeddings.size();
// 计算该标签的综合得分
labelsWithScores.add(new LabelWithScore(label, aggregatedScore(meanScore, maxScore)));
});
// 根据得分筛选并排序标签
return labelsWithScores.stream()
.filter(it -> it.score >= minScore)
// 按得分降序排序
.sorted(comparingDouble(labelWithScore -> 1 - labelWithScore.score))
.limit(maxResults)
.map(it -> it.label)
.collect(toList());
}
/**
* 计算平均得分和最大得分的加权综合得分
*/
private double aggregatedScore(double meanScore, double maxScore) {
return (meanToMaxScoreRatio * meanScore) + ((1 - meanToMaxScoreRatio) * maxScore);
}
/**
* 内部类,用于存储标签及其对应的得分
*/
private class LabelWithScore {
private final E label;
private final double score;
private LabelWithScore(E label, double score) {
this.label = label;
this.score = score;
}
}
}模型敏感词处理
大模型在开发和应用中,必须严格遵守法律法规,避免生成或传播违法、违规内容。同时,开发者和平台应采取多重措施,确保模型输出符合道德和法律标准,保护用户免受有害、冒犯或不适当内容的影响
背景和简介
sensitive-word是一个基于DFA(确定有限状态自动机)算法实现的高性能敏感词过滤工具,由GitHub用户houbb开发。它的主要特点和用法如下:
核心功能
检测文本是否包含敏感词
查找文本中的所有敏感词或第一个敏感词
替换敏感词(可自定义替换策略)
获取敏感词的标签信息
主要特性
支持忽略大小写、全角半角、中英文书写格式等
可以忽略数字的不同写法
支持繁简体转换
可以忽略重复词
支持邮箱、连续数字、网址、IPv4等特殊格式的检测
提供灵活的配置选项,如启用/禁用特定检测、自定义检测长度等
使用方法
1. 通过Maven引入依赖
<dependency>
<groupId>com.github.houbb</groupId>
<artifactId>sensitive-word</artifactId>
<version>0.21.0</version>
</dependency>
2. 基本使用示例
// 检查是否包含敏感词
boolean contains = SensitiveWordHelper.contains(text);
// 查找第一个敏感词
String firstWord = SensitiveWordHelper.findFirst(text);
// 查找所有敏感词
List<String> allWords = SensitiveWordHelper.findAll(text);
// 替换敏感词
String replaced = SensitiveWordHelper.replace(text);
3. 自定义配置
可以使用SensitiveWordBs类来自定义各种配置选项,例如:
SensitiveWordBs wordBs = SensitiveWordBs.newInstance()
// 使用默认的敏感词词库(黑名单)
.wordDeny(WordDenys.defaults())
// 使用默认的白名单词库,白名单中的词不会被视为敏感词,即使它们在黑名单中
.wordAllow(WordAllows.defaults())
// 忽略大小写,例如:"FuCk" 和 "fuck" 将被同等对待
.ignoreCase(true)
// 忽略全角和半角字符的区别,例如:"fuck" 和 "fuck" 将被同等对待
.ignoreWidth(true)
// 启用连续数字检测, 可用于检测电话号码、QQ号等
.enableNumCheck(true)
// 启用邮箱地址检测,可用于过滤包含邮箱地址的文本
.enableEmailCheck(true)
// 初始化敏感词过滤器, 这一步必须在所有配置完成后调用
.init();
// 使用配置好的过滤器检查文本是否包含敏感词
boolean contains = wordBs.contains(text);
总的来说,sensitive-word提供了一个功能丰富、性能优秀且易于使用的敏感词过滤解决方案,适用于各种需要文本审核的场景。
RAG Easy 快速上手
什么是 RAG?
检索增强生成(Retrieval-Augmented Generation,简称RAG)是一种结合大型语言模型(LLM)和外部知识库的技术,旨在提高生成文本的准确性和相关性。以下是对RAG的通俗介绍: RAG的基本概念 RAG的核心思想是通过引入外部知识源来增强LLM的输出能力。传统的LLM通常基于其训练数据生成响应,但这些数据可能过时或不够全面。RAG允许模型在生成答案之前,从特定的知识库中检索相关信息,从而提供更准确和上下文相关的回答
RAG 流程
RAG 过程分为两个阶段:索引(indexing)和检索(retrieval)。LangChain4j 提供了这两个阶段的工具。
索引阶段
在索引阶段,文档经过预处理以便在检索阶段进行高效搜索。对于向量搜索,通常包括清理文档、添加额外数据和元数据、将文档分割为小段(分块),将这些段落嵌入为向量,并存储在嵌入存储(向量数据库)中。
索引通常是离线进行的,可以通过定期任务(如每周重建索引)完成。

检索阶段
检索阶段通常是在线进行的,当用户提交问题时,从索引的文档中寻找相关信息。对于向量搜索来说,这通常包括将用户的查询嵌入为向量,并在嵌入存储中执行相似性搜索,找到相关的段落并将它们注入提示中,再发送给 LLM。

Easy RAG
LangChain4j 提供了”Easy RAG”功能,旨在让你快速上手 RAG,无需学习嵌入、选择向量存储或如何解析和分割文档等复杂步骤。只需指向你的文档,LangChain4j 将为你处理大部分细节。
1. 导入依赖:
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-easy-rag</artifactId>
</dependency>
2. 配置存储和Ai service
/**
* 嵌入存储 (简易内存存储)
*
* @return {@link InMemoryEmbeddingStore }<{@link TextSegment }>
*/
@Bean
public InMemoryEmbeddingStore<TextSegment> embeddingStore() {
return new InMemoryEmbeddingStore<>();
}
@Bean
public ChatAssistant assistant(ChatLanguageModel chatLanguageModel, EmbeddingStore<TextSegment> embeddingStore) {
return AiServices.builder(ChatAssistant.class)
.chatLanguageModel(chatLanguageModel)
.chatMemory(MessageWindowChatMemory.withMaxMessages(10))
.contentRetriever(EmbeddingStoreContentRetriever.from(embeddingStore))
.build();
}
3. 向量存储文档
Document document = FileSystemDocumentLoader.loadDocument("/Users/lengleng/Downloads/test.docx");
EmbeddingStoreIngestor.ingest(document,embeddingStore);
4. 测提提问
String result = assistant.chat("合同总金额");
进阶配置
/**
* 这个类负责将文档摄入嵌入存储。
* 它使用各种组件来转换、分割和嵌入文档,然后存储它们。
*/
public class EmbeddingStoreIngestor {
// 将输入文档转换为适合处理的格式
private final DocumentTransformer documentTransformer;
// 将文档分割成更小的段落
private final DocumentSplitter documentSplitter;
// 转换单个文本段落(例如,用于标准化或清理)
private final TextSegmentTransformer textSegmentTransformer;
// 为文本段落生成嵌入向量
private final EmbeddingModel embeddingModel;
// 存储生成的嵌入向量及其对应的文本段落
private final EmbeddingStore<TextSegment> embeddingStore;
}
// 使用构建器模式的示例
EmbeddingStoreIngestor
.builder()
.documentTransformer() // 设置文档转换器
.documentSplitter() // 设置文档分割器
.embeddingModel() // 设置嵌入模型
.embeddingStore() // 设置嵌入存储
.build() // 构建EmbeddingStoreIngestor实例
.ingest(document); // 将文档摄入嵌入存储RAG API 基础
LangChain4j 是一个强大的 Java 库,提供了丰富的 API 来简化构建自定义 RAG(检索增强生成)管道的过程。本指南将详细介绍 LangChain4j 的主要组件和 API,从简单到复杂的多种管道实现。

2. 核心概念
2.1 Document (文档)
Document 类表示一个完整的文档,例如单个 PDF 文件或网页。
主要方法:
Document.text(): 返回文档的文本内容Document.metadata(): 返回文档的元数据Document.toTextSegment(): 将Document转换为TextSegmentDocument.from(String, Metadata): 从文本和元数据创建DocumentDocument.from(String): 从文本创建不带元数据的Document
2.2 Metadata (元数据)
Metadata 存储文档的额外信息,如名称、来源、最后更新时间等。
主要方法:
Metadata.from(Map): 从Map创建MetadataMetadata.put(String key, String value): 添加元数据条目Metadata.getString(String key)/getInteger(String key): 获取指定类型的元数据值Metadata.containsKey(String key): 检查是否包含指定键Metadata.remove(String key): 移除指定键的元数据条目Metadata.copy(): 复制元数据Metadata.toMap(): 将元数据转换为Map
2.3 TextSegment (文本片段)
TextSegment 表示文档的一个片段,专用于文本信息。
主要方法:
TextSegment.text(): 返回文本片段的内容TextSegment.metadata(): 返回文本片段的元数据TextSegment.from(String, Metadata): 从文本和元数据创建TextSegmentTextSegment.from(String): 从文本创建不带元数据的TextSegment
2.4 Embedding (嵌入)
Embedding 类封装了一个数值向量,表示嵌入内容的语义含义。
主要方法:
Embedding.dimension(): 返回嵌入向量的维度CosineSimilarity.between(Embedding, Embedding): 计算两个嵌入向量的余弦相似度Embedding.normalize(): 对嵌入向量进行归一化
3. 文档处理
3.1 Document Loader (文档加载器)
LangChain4j 提供了多种文档加载器:
FileSystemDocumentLoader: 从文件系统加载文档UrlDocumentLoader: 从 URL 加载文档AmazonS3DocumentLoader: 从 Amazon S3 加载文档AzureBlobStorageDocumentLoader: 从 Azure Blob 存储加载文档GitHubDocumentLoader: 从 GitHub 仓库加载文档TencentCosDocumentLoader: 从腾讯云 COS 加载文档
3.2 Document Parser (文档解析器)
用于解析不同格式的文档:
TextDocumentParser: 解析纯文本文件ApachePdfBoxDocumentParser: 解析 PDF 文件ApachePoiDocumentParser: 解析 MS Office 文件格式ApacheTikaDocumentParser: 自动检测并解析几乎所有文件格式
示例:
// 加载单个文档
Document document = FileSystemDocumentLoader.loadDocument("/path/to/file.txt", new TextDocumentParser());
// 加载目录下的所有文档
List<Document> documents = FileSystemDocumentLoader.loadDocuments("/path/to/directory", new TextDocumentParser());
3.3 Document Transformer (文档转换器)
DocumentTransformer 用于对文档执行各种转换,如清理、过滤、增强或总结。
目前提供的转换器:
HtmlToTextDocumentTransformer: 从 HTML 中提取文本内容和元数据
3.4 Document Splitter (文档拆分器)
用于将文档拆分成更小的片段:
DocumentByParagraphSplitter: 按段落拆分DocumentBySentenceSplitter: 按句子拆分DocumentByWordSplitter: 按单词拆分DocumentByCharacterSplitter: 按字符拆分DocumentByRegexSplitter: 按正则表达式拆分
使用步骤:
实例化
DocumentSplitter并指定TextSegment的大小和重叠字符数调用
split(Document)或splitAll(List<Document>)方法DocumentSplitter将文档拆分成小片段,并组合为TextSegment
4. 嵌入处理
4.1 Embedding Model (嵌入模型)
EmbeddingModel 接口表示一种将文本转换为 Embedding 的模型。
主要方法:
EmbeddingModel.embed(String): 嵌入指定文本EmbeddingModel.embed(TextSegment): 嵌入指定TextSegmentEmbeddingModel.embedAll(List<TextSegment>): 嵌入多个TextSegmentEmbeddingModel.dimension(): 返回嵌入向量的维度
4.2 Embedding Store (嵌入存储)
EmbeddingStore 接口表示一个嵌入存储库(向量数据库),用于存储和高效搜索相似的嵌入。
主要方法:
EmbeddingStore.add(Embedding): 添加嵌入并返回随机 IDEmbeddingStore.addAll(List<Embedding>): 添加多个嵌入并返回随机 ID 列表EmbeddingStore.search(EmbeddingSearchRequest): 搜索最相似的嵌入EmbeddingStore.remove(String id): 删除指定 ID 的嵌入
4.3 Embedding Store Ingestor (嵌入存储摄取器)
EmbeddingStoreIngestor 负责将文档嵌入并存储到 EmbeddingStore 中。
示例:
EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder()
.embeddingModel(embeddingModel)
.embeddingStore(embeddingStore)
.build();
ingestor.ingest(document1);
可以通过指定 DocumentTransformer 和 DocumentSplitter,在嵌入前对文档进行转换和拆分。
5. 构建 RAG 管道
使用 LangChain4j 构建 RAG 管道的一般步骤:
加载文档: 使用适当的
DocumentLoader和DocumentParser加载文档转换文档: 使用
DocumentTransformer清理或增强文档(可选)拆分文档: 使用
DocumentSplitter将文档拆分为更小的片段嵌入文档: 使用
EmbeddingModel将文档片段转换为嵌入向量存储嵌入: 使用
EmbeddingStore存储嵌入向量检索相关内容: 根据用户查询,从
EmbeddingStore检索最相关的文档片段生成响应: 将检索到的相关内容与用户查询一起提供给语言模型,生成最终响应
6. 最佳实践
根据具体需求选择合适的文档拆分策略
使用自定义的
DocumentTransformer来清理和增强文档选择合适的嵌入模型和嵌入存储以平衡性能和准确性
定期更新和维护嵌入存储,以确保信息的时效性
对检索结果进行后处理,如重新排序或过滤,以提高相关性
7. 结语
LangChain4j 提供了构建高效 RAG 系统所需的全套工具。通过灵活组合这些组件,您可以创建适合特定用例的自定义 RAG 管道。随着项目的发展,不断优化和调整各个组件,以提高系统的整体性能和准确性。
RAG API 增强

检索增强器(Retrieval Augmentor)
RetrievalAugmentor 是 RAG(检索增强生成)流程的核心,它通过从不同的数据源中检索相关内容来增强用户的消息。
在创建 AI service 时,可以指定 RetrievalAugmentor 实例:
@Bean
public ChatAssistant assistant(ChatLanguageModel chatLanguageModel, EmbeddingStore<TextSegment> embeddingStore) {
DefaultRetrievalAugmentor retrievalAugmentor = DefaultRetrievalAugmentor.builder()
.queryTransformer() // 查询增强
.contentRetriever() // 内容源 单个直接配置
.queryRouter(new DefaultQueryRouter())// 多个内容源,路由
.contentAggregator() // 匹配结果聚合
.contentInjector() // 结果提示词注入
.executor() // 并行化
.build();
return AiServices.builder(ChatAssistant.class)
.chatLanguageModel(chatLanguageModel)
.chatMemory(MessageWindowChatMemory.withMaxMessages(10))
.retrievalAugmentor(retrievalAugmentor)
.build();
}
每次调用 AI 服务时,都会自动使用这个增强器来处理当前的用户消息。你可以使用默认的增强器实现,也可以根据需求自定义。
默认检索增强器
LangChain4j 提供了开箱即用的 RetrievalAugmentor 实现:DefaultRetrievalAugmentor。它适用于大多数的 RAG 场景。这个实现的灵感来源于 LangChain 博客文章 和 相关论文。
查询(Query)
Query 代表用户的查询请求,包含查询的文本以及相关的元数据。
查询元数据
Query 中的 Metadata 包含在 RAG 流程中有用的上下文信息,例如:
Metadata.userMessage():表示用户输入的原始消息。Metadata.chatMemoryId():一个用于标识用户的ID,可以应用在数据访问限制或过滤上。Metadata.chatMemory():之前的所有对话消息,用于理解查询的上下文。
查询转换器(Query Transformer)
QueryTransformer 用于将原始查询转换为一个或多个新的查询,以提高检索的准确性。常见的查询优化方式包括:
查询压缩:压缩冗长的对话,生成一个简明的查询。
查询扩展:将简单的查询扩展为多个相关的查询。
查询重写:对查询进行改写,使其更适合检索。
示例:
QueryTransformer transformer = new CompressingQueryTransformer();
默认查询转换器
DefaultQueryTransformer 是最简单的实现,它直接传递原始查询而不进行任何修改。压缩查询转换器
CompressingQueryTransformer 使用大语言模型(LLM)压缩查询和对话上下文,生成一个更简洁、独立的查询。例如:
用户:告诉我关于John Doe的信息。
AI:John Doe 是一个著名作家。
用户:他住在哪里?
对于”他住在哪里?“这样的查询,CompressingQueryTransformer 会自动转换为”John Doe 住在哪里?“,以便更精准地检索信息。
扩展查询转换器
ExpandingQueryTransformer 可以将简单的查询扩展为多个不同的表达方式,从而提高相关内容的覆盖面。
内容(Content)
Content 代表系统从数据源中检索到的与查询相关的内容。目前支持的主要是文本内容(TextSegment),未来可能会扩展支持其他模态,如图像、音频、视频等。
内容检索器(Content Retriever)
ContentRetriever 根据用户的查询从底层数据源中获取内容,数据源可以是:
嵌入向量存储
全文搜索引擎
向量与全文检索结合
网络搜索引擎
SQL数据库
知识图谱等
嵌入存储内容检索器
EmbeddingStoreContentRetriever 使用嵌入模型将查询转化为向量,并从嵌入存储中检索相关的内容。
示例代码:
EmbeddingStore embeddingStore = ...
EmbeddingModel embeddingModel = ...
ContentRetriever contentRetriever = EmbeddingStoreContentRetriever.builder()
.embeddingStore(embeddingStore)
.embeddingModel(embeddingModel)
.maxResults(3) // 返回最多3条结果
.dynamicMaxResults(query -> 3) // 根据查询动态指定maxResults
.minScore(0.75) // 过滤分数低于0.75的内容
.dynamicMinScore(query -> 0.75) // 根据查询动态指定minScore
.filter(metadataKey("userId").isEqualTo("12345")) // 过滤指定用户的内容
.dynamicFilter(query -> {
String userId = getUserId(query.metadata().chatMemoryId());
return metadataKey("userId").isEqualTo(userId); // 动态过滤
})
.build();
网络搜索内容检索器
WebSearchContentRetriever 通过 WebSearchEngine 从互联网上检索相关内容。
示例代码:
WebSearchEngine googleSearchEngine = GoogleCustomWebSearchEngine.builder()
.apiKey(System.getenv("GOOGLE_API_KEY"))
.csi(System.getenv("GOOGLE_SEARCH_ENGINE_ID"))
.build();
ContentRetriever contentRetriever = WebSearchContentRetriever.builder()
.webSearchEngine(googleSearchEngine)
.maxResults(3)
.build();
查看完整示例请参考这里。
SQL数据库内容检索器
SqlDatabaseContentRetriever 是用于从SQL数据库检索数据的实验性实现。更多信息可参考相关javadoc文档。
Azure AI 搜索内容检索器
AzureAiSearchContentRetriever 在 langchain4j-azure-ai-search 模块中可用。
Neo4j内容检索器
Neo4jContentRetriever 可用于从Neo4j数据库中检索与查询相关的内容。
查询路由器(Query Router)
QueryRouter 负责将查询分配到合适的内容检索器。
默认查询路由器
DefaultQueryRouter 将每个查询路由到所有配置的内容检索器。
语言模型查询路由器
LanguageModelQueryRouter 使用大语言模型(LLM)决定应该将查询发送到哪个检索器。
并行化处理
当只有一个查询和一个检索器时,DefaultRetrievalAugmentor 会在单线程中执行查询和检索。否则,它会使用 Executor 并行处理多个查询和检索任务。默认情况下,系统会使用一个修改后的 Executors.newCachedThreadPool() 来实现这一功能,你也可以提供自定义的 Executor:
DefaultRetrievalAugmentor augmentor = DefaultRetrievalAugmentor.builder()
.executor(executor)
.build();RAG 结果重排

RRF
基本概念
Reciprocal Rank Fusion (RRF) 是一种用于结合多个排序结果的简单而有效的算法。它通过计算每个候选项在多个列表中的排名倒数,然后将这些倒数相加,从而得出一个”融合分数”,并根据该分数对候选项进行重新排序。
示例
假设你和三个朋友在寻找一本丢失的书,每个人列出了最有可能找到书的地点,并按从高到低的顺序进行排序。RRF 就是结合这些排序结果,帮助找到最有可能的地点。
列表数据
朋友A的列表:
书架
桌子
床下
朋友B的列表:
床下
书架
桌子
朋友C的列表:
桌子
书架
床下
RRF 计算过程
我们为每个地点计算在每个列表中的排名倒数,然后将这些倒数相加,得到融合分数。
书架
在朋友A的列表中排名第1:11=111=1
在朋友B的列表中排名第2:12=0.521=0.5
在朋友C的列表中排名第2:12=0.521=0.5
总分: 1+0.5+0.5=21+0.5+0.5=2
床下
在朋友A的列表中排名第3:13=0.3331=0.33
在朋友B的列表中排名第1:11=111=1
在朋友C的列表中排名第3:13=0.3331=0.33
总分: 0.33+1+0.33=1.660.33+1+0.33=1.66
桌子
在朋友A的列表中排名第2:12=0.521=0.5
在朋友B的列表中排名第3:13=0.3331=0.33
在朋友C的列表中排名第1:11=111=1
总分: 0.5+0.33+1=1.830.5+0.33+1=1.83
排序结果
最后,我们根据每个地点的融合分数排序:
书架: 2
桌子: 1.83
床下: 1.66
因此,书架是最有可能找到书的地点。
这个例子清楚地展示了RRF如何结合多个列表进行排序,从而提高结果的精确性。这种方法常用于信息检索和文档重排序中。
Reranker
重排序模型的核心是计算用户查询与候选文档之间的语义匹配度,并根据该匹配度对结果进行重新排序。通过这种方式,语义排序的效果能够得到显著提升。它的原理是对每个候选文档计算与用户查询的相关性分数,并按相关性高低输出排序后的文档列表。

Jina AI提供了一个强大的reranker模型,可以轻松集成到LangChain4j项目中。以下是使用Jina Reranker的基本步骤。
Maven 依赖
在你的Maven项目中添加以下依赖:
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-jina</artifactId>
</dependency>
基本用法
以下是在LangChain4j中使用Jina Reranker的基本示例:
// 创建Jina评分模型
ScoringModel scoringModel = JinaScoringModel.builder()
.apiKey(System.getenv("JINA_API_KEY"))
.modelName("jina-reranker-v2-base-multilingual")
.build();
// 创建内容聚合器
ContentAggregator contentAggregator = ReRankingContentAggregator.builder()
.scoringModel(scoringModel)
// 可以添加其他配置选项
.build();
// 创建检索增强器
RetrievalAugmentor retrievalAugmentor = DefaultRetrievalAugmentor.builder()
// 添加其他必要的配置
.contentAggregator(contentAggregator)
.build();
// 构建AI服务
Assistant assistant = AiServices.builder(Assistant.class)
.chatLanguageModel(/* 配置你的语言模型 */)
.retrievalAugmentor(retrievalAugmentor)
.build();
关键组件说明
JinaScoringModel: Jina Reranker的核心组件,需要API密钥和模型名称。
ReRankingContentAggregator: 使用评分模型来重新排序检索到的内容。
RetrievalAugmentor: 整合检索和重新排序过程的高级组件。
AiServices: LangChain4j的工具类,用于构建集成了各种功能的AI服务。
注意事项
进阶使用
调整重新排序的参数,如考虑的结果数量。
结合其他检索技术,如向量搜索。
实现自定义的评分逻辑。
RRF vs Reranker 比较
结论
RRF和Reranker是两种不同但互补的技术。RRF更适合于多源数据的融合,而Reranker则专注于提高单一查询结果集的质量和相关性。在实际应用中,可以根据具体需求选择适当的方法,或将两者结合使用以达到更好的信息检索效果。通过集成像Jina Reranker这样的工具到LangChain4j项目中,可以显著提高检索结果的质量,这对于构建高性能的问答系统、搜索引擎或任何需要精确信息检索的应用程序都是非常有价值的。
RAG 进阶分享

上下文检索:显著提高RAG性能的方法
对于AI模型在特定上下文中使用,通常需要访问背景知识。例如,客户支持聊天机器人需要了解特定业务的相关知识,而法律分析师机器人则需要了解大量过往案例。
开发者通常使用检索增强生成(RAG)来增强AI模型的知识。RAG是一种从知识库中检索相关信息并将其附加到用户提示中的方法,显著增强了模型的响应。问题在于传统的RAG解决方案在编码信息时会丢失上下文,这通常会导致系统无法从知识库中检索到相关信息。
在本文中,我们概述了一种显著提高RAG检索步骤性能的方法。该方法称为”上下文检索”,并使用两种子技术:上下文向量(Contextual Embeddings)和上下文BM25。这种方法可以将检索失败率降低49%,如果再结合重排序技术,甚至可以降低67%。这些表示显著的性能提升,直接提高了下游任务的性能。
你可以轻松地使用Claude部署自己的上下文检索解决方案,只需参考我们的食谱。
使用更长的提示的注意事项
有时候最简单的方法是最好的。如果你的知识库小于200,000个标记(大约500页的材料),你可以将整个知识库包含在提供给模型的提示中,而不需要RAG或类似的方法。
几周前,我们为Claude发布了提示缓存,使这种方法显著更快和更节省成本。开发者现在可以在API调用之间缓存经常使用的提示,将延迟减少超过2倍,并将成本降低多达90%(你可以通过阅读我们的提示缓存食谱来了解它是如何工作的)。
然而,随着你的知识库的增长,你需要一个更可扩展的解决方案。这就是上下文检索的用武之地。
RAG:扩展到更大的知识库
对于那些不适合上下文窗口的知识库,RAG是典型的解决方案。RAG通过以下步骤预处理知识库:
将知识库(文档的”语料库”)分解为较小的文本块,通常不超过几百个标记;
使用向量模型将这些块转换为向量向量,这些向量编码意义;
将这些向量存储在允许通过语义相似性搜索的向量数据库中。
在运行时,当用户向模型输入查询时,使用向量数据库根据语义相似性找到最相关的块。然后,将最相关的块添加到发送给生成模型的提示中。
虽然向量模型在捕捉语义关系方面表现出色,但它们可能会错过关键的精确匹配。幸运的是,有一种古老的技术可以在这方面提供帮助。BM25(最佳匹配25)是一种使用词汇匹配的排名函数,用于找到精确的单词或短语匹配。它特别适用于包含唯一标识符或技术术语的查询。
BM25 通过利用 TF-IDF(词频-逆文档频率)概念来工作。TF-IDF 衡量一个词在一个集合中的文档中的重要性。BM25 通过考虑文档长度并应用饱和函数来细化这一点,该函数有助于防止常见词在结果中占据主导地位。
BM25 可以在语义向量失败的地方成功:假设用户在一个技术支持数据库中查询”错误代码 TS-999”。一个向量模型可能会找到关于错误代码的一般内容,但可能会错过确切的”TS-999”匹配。BM25 寻找这个特定的文本字符串来识别相关的文档。
RAG 解决方案可以通过使用以下步骤结合向量和 BM25 技术来更准确地检索最相关的块:
将知识库(文档的”语料库”)分解为较小的文本块,通常不超过几百个标记;
为这些块创建 TF-IDF 编码和语义向量;
使用 BM25 根据确切匹配找到顶部块;
使用向量根据语义相似性找到顶部块;
使用 rank fusion 技术结合和去重 (3) 和 (4) 的结果;
将顶部块添加到提示中以生成响应。
通过结合 BM25 和向量模型,传统的 RAG 系统可以提供更全面和准确的结果,平衡精确的词匹配与更广泛的语义理解。

这种方法允许你有效地扩展到巨大的知识库,远远超过单个提示所能容纳的范围。但这些传统的 RAG 系统有一个显著的限制:它们经常破坏上下文。
传统RAG中的上下文困境
在传统的 RAG 中,文档通常被拆分为较小的块以进行高效检索。虽然这种方法对许多应用效果很好,但当单个块缺乏足够的上下文时,可能会导致问题。
例如,想象一下,你的知识库中包含了一个财务信息集合(例如,美国 SEC 文件),并且你收到了以下问题:“ACME 公司在 2023 年第二季度的收入增长是多少?”
一个相关的块可能包含以下文本:“公司收入比上一季度增长了 3%。” 然而,这个块本身没有指明它指的是哪家公司或相关时间范围,这使得很难检索到正确的信息或有效地使用信息。
引入上下文检索
上下文检索通过在每个块之前添加特定于块的解释性上下文,在向量(“上下文向量”)和创建 BM25 索引(“上下文 BM25”)之前解决了这个问题。
让我们回到我们的 SEC 文件集合示例。以下是一个块可能被转换的方式:
original_chunk = "公司收入比上一季度增长了 3%。"
contextualized_chunk = "该段落摘自ACME公司2023年第二季度的SEC文件;上一季度的收入为3.14亿美元。该公司的收入比上一季度增长了3%。"
值得注意的是,其他方法已经提出使用上下文来提高检索性能。其他建议包括:在块中添加通用文档摘要(我们尝试过并发现效果有限),假设文档向量,以及基于摘要的索引(我们评估过并发现性能较低)。这些方法与本文提出的方法不同。
实现上下文检索
当然,手动注释知识库中的数千甚至数百万个块将是一项极其繁重的工作。为了实现上下文检索,我们求助于Claude。我们已经编写了一个提示,指示模型提供简洁的、块特定的上下文,使用整个文档的上下文解释块。我们使用以下Claude 3 Haiku提示为每个块生成上下文:
<document>
{{WHOLE_DOCUMENT}}
</document>
Here is the chunk we want to situate within the whole document
<chunk>
{{CHUNK_CONTENT}}
</chunk>
Please give a short succinct context to situate this chunk within the overall document for the purposes of improving search retrieval of the chunk. Answer only with the succinct context and nothing else.
生成的上下文文本,通常为50-100个标记,在向量之前和创建BM25索引之前附加到块。
以下是预处理流程的实际应用:

使用提示缓存减少上下文检索的成本
上下文检索在Claude中以低成本实现,得益于上述的特殊提示缓存功能。使用提示缓存,你不需要为每个块传递参考文档。你只需将文档加载到缓存中一次,然后引用之前缓存的内容。假设每个块有800个标记,8k标记的文档,50个标记的上下文指令,每个块有100个标记的上下文,生成上下文块的一次性成本为每百万文档标记1.02美元。
方法论
我们尝试了各种知识领域(代码库、小说、ArXiv论文、科学论文)、向量模型、检索策略和评估指标。我们在附录II中包含了一些我们用于每个领域的示例问题和答案。
下图显示了所有知识领域中所有向量配置的平均性能,使用最佳向量配置(Gemini Text 004)检索前20个块。我们使用1减去召回@20作为评估指标,该指标测量在20个块中未检索到的相关文档的百分比。你可以在附录中查看完整的结果——上下文化在所有评估的向量源组合中都提高了性能。
性能提升
我们的实验表明:
上下文向量将前20个块的检索失败率降低了35% (5.7% → 3.7%).
结合上下文向量和上下文BM25将前20个块的检索失败率降低了49% (5.7% → 2.9%).

实现考虑
在实现上下文检索时,有几点需要考虑:
Chunk boundaries: 考虑如何将文档拆分为块。块大小、块边界和块重叠的选择会影响检索性能。
Embedding model: 上下文检索在所有测试的向量模型中都提高了性能,但某些模型可能比其他模型表现更好。我们发现 Gemini 和 Voyage 向量特别有效。
Custom contextualizer prompts: 虽然我们提供的通用提示效果很好,但你可以使用针对特定领域或用例的提示来实现更好的结果(例如,包括一个可能只在知识库中的其他文档中定义的关键术语词汇表)。
Number of chunks: 将更多块添加到上下文窗口中会增加包含相关信息的机会。然而,更多的信息可能会分散模型的注意力,因此有一个限制。我们尝试了5、10和20个块,发现使用20个块是这些选项中性能最好的(见附录中的比较),但值得在特定用例上进行实验。
Always run evals: 响应生成可以通过传递上下文块并区分上下文和块来改进。
进一步提高性能的重排序
在最后一步中,我们可以将上下文检索与另一种技术结合使用,以获得更多的性能提升。在传统的RAG中,AI系统搜索其知识库以找到可能相关的信息块。使用大型知识库时,此初始检索通常会返回大量块——有时多达数百个,具有不同的相关性和重要性。
重排序是一种常用的过滤技术,可以确保只将最相关的块传递给模型。重排序提供更好的响应并减少成本和延迟,因为模型处理的信息更少。关键步骤如下:
执行初始检索以获取可能相关的顶部块(我们使用前150个);
将前N个块和用户的查询传递给重排序模型;
使用重排序模型,根据其与提示的相关性和重要性为每个块打分,然后选择前K个块(我们使用前20个);
将前K个块传递给模型作为上下文,以生成最终结果。

性能提升
市场上有几种重排序模型。我们使用 Cohere 重排序器进行了测试。Voyage 也提供了一个重排序器,但我们没有时间测试它。我们的实验表明,在各种领域中,添加重排序步骤可以进一步优化检索。
具体来说,我们发现重排序的上下文向量和上下文 BM25 将前 20 个块的检索失败率降低了 67%(5.7% → 1.9%)。

成本和延迟考虑
重排序的一个重要考虑因素是对延迟和成本的影响,特别是在重排序大量块时。由于重排序在运行时添加了额外的步骤,即使重排序器并行对所有块进行评分,它也不可避免地会增加一些延迟。在重排序更多块以获得更好性能与重排序更少块以降低延迟和成本之间存在固有的权衡。我们建议在您的特定用例上尝试不同的设置,以找到合适的平衡点。
结论
我们进行了大量测试,比较了上述所有技术的不同组合(向量模型、使用 BM25、使用上下文检索、使用重排序器以及检索的前 K 个结果总数),涵盖了各种不同的数据集类型。以下是我们的发现总结:
向量+BM25 比单独使用向量更好;
在我们测试的向量中,Voyage 和 Gemini 的效果最好;
将前 20 个块传递给模型比仅传递前 10 个或前 5 个更有效;
为块添加上下文大大提高了检索准确性;
使用重排序比不使用重排序更好;
所有这些优势都可以叠加:为了最大化性能提升,我们可以结合上下文向量(来自 Voyage 或 Gemini)、上下文 BM25、重排序步骤,并将 20 个块添加到提示中。
我们鼓励所有使用知识库的开发者使用我们的指南来尝试这些方法,以解锁新的性能水平。
附录 I
以下是各数据集、向量提供商、是否使用 BM25 补充向量、是否使用上下文检索以及是否使用重排序的前 20 个检索结果的细分。
有关前 10 个和前 5 个检索结果的细分以及每个数据集的示例问题和答案,请参见附录 II。

各数据集和向量提供商的 1 减去召回率 @ 20 的结果。